The Forced Data Loss
General data protection regulation. ePrivacy directive. Intelligent tracking prevention. Enhanced Tracking Prevention. Ad-Blockers. Virus-Scanners. And the list keeps on growing… The challenges for businesses when it comes to collecting their (first party) data on their website have never been bigger. And the situation is getting increasingly worse. So the question arises: How good or bad is the data quality in your martech tools today with client-side tracking?
Introduction
General data protection regulation. ePrivacy directive. Intelligent tracking prevention. Enhanced Tracking Prevention. Ad-Blockers. Virus-Scanners. And the list keeps on growing…
The challenges for businesses when it comes to collecting your (first party) data on your website have never been bigger. And the situation is getting increasingly worse.
So the question arises: How good or bad is the data quality in your martech tools with client-side tracking today?
This blogpost is dedicated to providing you with an easy step by step guide to calculate the percentage of data you lose – your current “forced data loss” as we have come to call it.
For the purpose of this article we define data quality as having these three attributes:
- Completeness – i.e. you collect all data (separate data points if necessary anonymised)
- Accuracy – i.e. data needs to be connected for correct insights (like a customer journey)
- Validity – no extrapolated data based on shaky assumptions and unrepresentative data
Having said that, let’s categories and analyse the “ big data gaps” from an objective point of view. The numbers we use in the example are approximations from previous experiences. Your individual data loss might be different.
We will also provide an explanation as to why this data is lost, because we believe it is really important to understand the intention behind these mechanisms. This, in turn, allows the definition of proper solutions to regain your desired data quality.
STEP 1
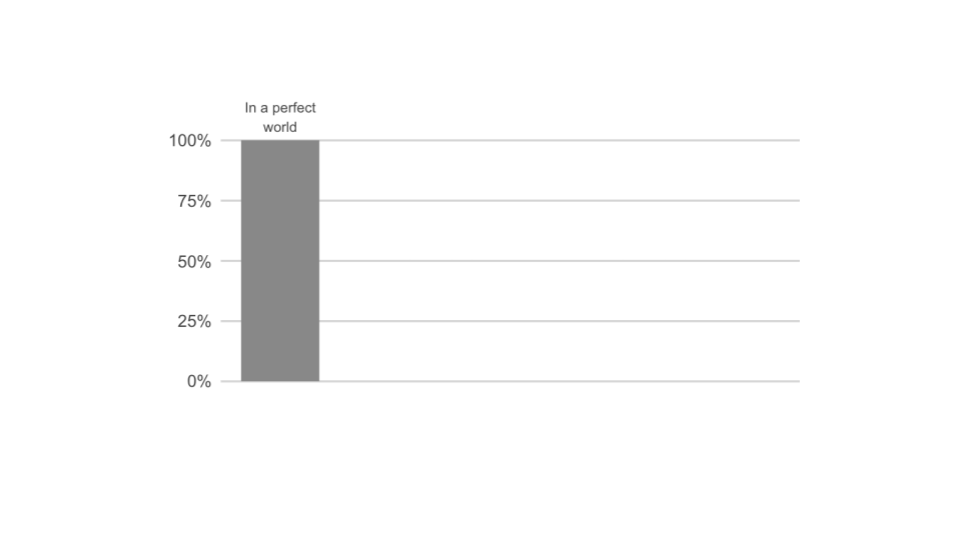
Start from the ideal scenario
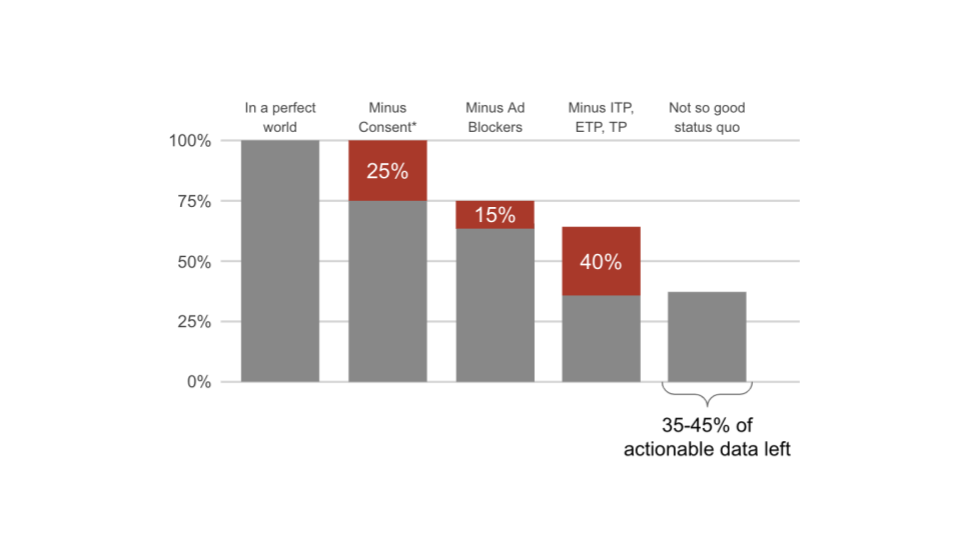
In a perfect world you would have 100% of your data while protecting the privacy of your user. This will be the benchmark for the next steps.
STEP 2
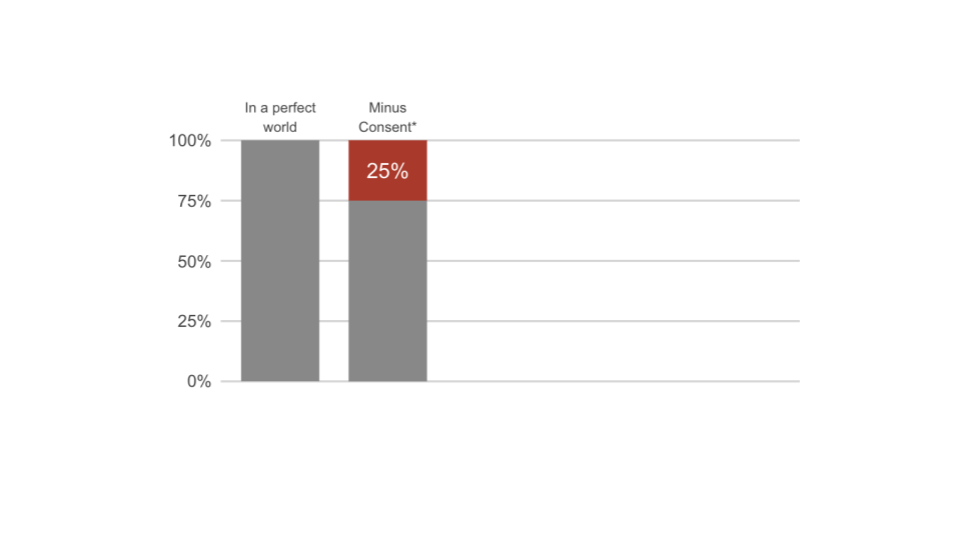
Subtract consent
CMPs have detailed statistics about companies’ consent rates. Take those to subtract the first pool of missing data.
Why is this data really lost:
In order to protect the privacy of the users, organisations need to actively ask for consent to 1) drop a cookie on the device of the user and 2) process personal data and share it with third party providers. Clear definitions and exceptions exist in both cases but the protection of users privacy is unequivocal .
STEP 3
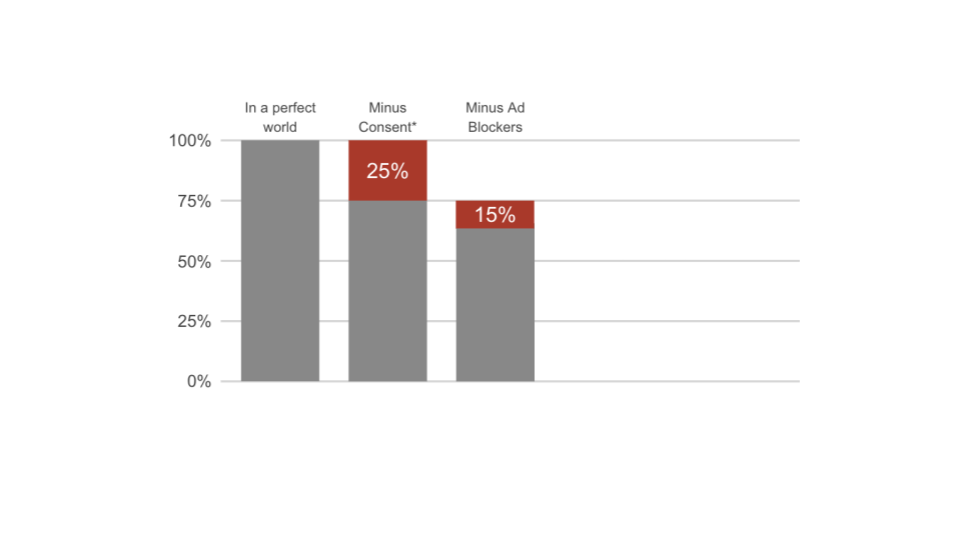
Subtract ad-blockersVarious
ad-blockers impair data collection on your website. Based on our experience this percentage is about 15% (less if you have much mobile traffic).
Why is this data really lost:
Ad-blockers are installed for the purpose of inhibiting ads to be played out on predefined spaces on websites. In particular, users want to prevent ads from “following” them across the web.
STEP 4
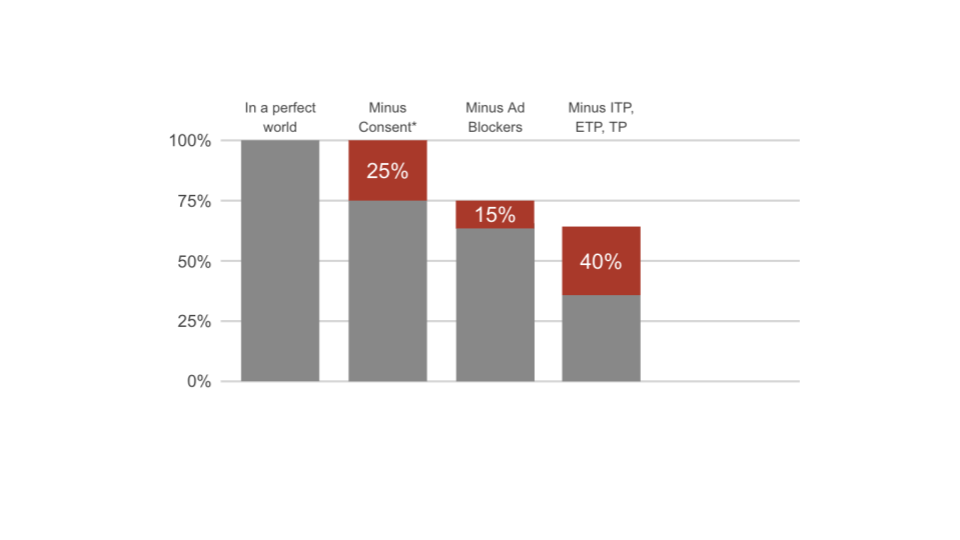
Subtract tracking preventions
Safari, Firefox and Edge inhibit tracking and data collection already by default. The impact here depends very much on your respective browser split.
Why is this data really lost:
Similar to Ad-blockers, also tracking preventions inhibit data collection to a certain degree. In particular, these technologies constrain the use of third (and fake first) party cookies, deleting them after a certain time period (ranges between 1 day to 30 days).
STEP 5
Realise the catastrophic result
This is the dismal result for your current data quality. This is the data with which every one of your Martech tools has to work. Because of the way tracking is done on the client in combination with the rising number of regulations companies lose north of 60% of their data.
Consequently, this has a massive impact on the effectiveness and efficiency of your martech stack (“Bullshit in, bullshit out”) and impedes your decision-making capabilities (probably more than you think).
Conclusion
Thus, to come back to the goal of this blogpost, please check for yourself to which degree you are already affected by these externalities and also do research into how this could worsen.
And to those that still do not track in a compliant fashion and track with tools illegally without consent – a time soon will come where you will be forced to switch your strategy – the latest when the data protection agencies knock on your doors.
We hope you understand now, that your data quality is a very critical challenge moving into 2022. It has declined and will continue to do so should you stick with client-side tracking (aside from other important problems like compliance or not being in control of the data you collect).
Data-driven marketing is at the heart of any company’s digital activities. Are you sure you can “successfully” do it with 60% of your data missing?
You hate to lose? We got you covered. JENTIS can collect pseudonymized data and is also unaffected by tracking preventions / ad-blockers.
More information
Data Privacy Update: What the U.S. Administration's Approach means for the DPF and European businesses
The Data Privacy Framework is under pressure – find out what this means for GDPR-compliant companies processing data in the US.
eCommerce strategy for Black Week: trends, traffic peaks & smarter Ad Spend
Black Week is long past being just a Friday. Discover which ecommerce strategy matters now – with a focus on performance, data, and agility.
What is a Tag Manager? Functions, Tools, and Benefits
Tag managers are the backbone of modern marketing setups – they align speed, control, and data privacy, making data-driven work truly efficient.